
Exploring Mistral: A Comparative Analysis with OpenAI GPT-3.5-Turbo in Multilingual Contexts (English and Spanish)
Juan David López
12/14/20235 min read
A brief Look at AI Model Performances in Multilingual Contexts.
Introduction:
In the dynamic realm of artificial intelligence, the rise of advanced language models heralds a new era of possibilities. Among these, the Mixtral model particularly piqued my interest, especially for its purported proficiency in handling Spanish. As an AI enthusiast and a developer of BrainBox, a cutting-edge tool designed for Retrieval Augmented Generation (RAG) in enterprise applications, I was intrigued to see how Mistral stacks up in multilingual real-world scenarios. My experiment was more than just an academic exercise; it was a quest to explore whether Mistral could indeed rival or even surpass OpenAI's GPT-3.5-Turbo in our Brainbox RAG system.
Methodology:
I used Anyscale Endpoints and the OpenAI package for this experiment, appreciating Anyscale for its affordability and seamless integration. The following configuration was applied to both models:


My primary source for the comparison was the Gemini Technical Report PDF. I evaluated the models based on their responses to identical questions posed in Spanish and English, examining their multilingual proficiency and the relevance and accuracy of their answers.
It's important to note the following:
The Genimi technical report is in English.
The Prompt Used for RAG in BrainBox is in Spanish.
Questions:
Question 1: "¿Cuál es la ventana de contexto?" ("What is the context Window?")
Mixtral's Response:


Observation: Mistral delivered an extensive answer detailing the capabilities of Gemini models. It explained their multimodal nature, emphasizing their 32k context length and ability to process varied inputs like text, audio, and visuals. The response, while comprehensive, veered into details about the model's training and features, some of which were not directly relevant to the question. This verbosity, although informative, stretched beyond the query's scope.
OpenAI GPT-3.5's Response:

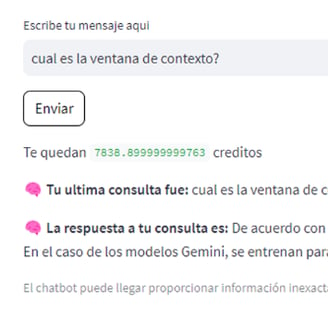
Observation: In contrast, GPT-3.5 provided a succinct and relevant answer, directly addressing the query's essence. It concisely defined the context window as the amount of text Gemini models can handle in a single step, specifically stating the 32k token limit.
Question 2: "¿De qué se trata el texto?" ("What is the text about?")
Mistral's Response:


Observation: Mixtral, unfortunately, couldn't provide a relevant answer to this question, highlighting a limitation in its ability to grasp the context of less specific queries.
OpenAI GPT-3.5's Response:

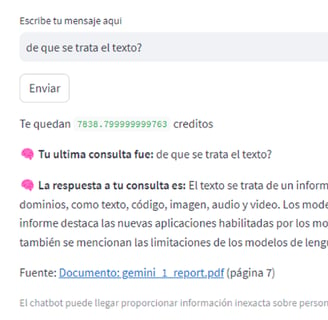
Observation: GPT-3.5 adeptly summarized the technical report, mentioning its focus on the Gemini models' capabilities across different domains, such as text, code, and multimedia. It noted the models' significant achievements and potential applications, along with the challenges in language model reliability and the need for further research.
Final Thoughts on Spanish Queries:
In a test comparing Mistral and OpenAI GPT-3.5, Mistral's answers were long and very detailed, sometimes more than needed. On the other hand, OpenAI GPT-3.5 gave shorter, clearer answers that were right on point. Mistral had trouble with vague questions, while OpenAI GPT-3.5 was good at giving quick summaries that matched the questions well.
Experiment with English Queries:
Curious about the models' responses in English, I posed the same questions in English to observe any differences.
Question 1 (English Version): "What is the context window?"
Mixtral's Response:


Observation: Mistral correctly identified the context window as the maximum length of the input sequence that the model can process, specifically 32k tokens, as stated in the Gemini report.
OpenAI GPT-3.5's Response:


Observation: Surprisingly, GPT-3.5 responded in Spanish, an unexpected twist given the query was in English. This suggests a potential influence of the original Spanish prompt on the model's language selection.
Question 2 (English Version): "What is the text about?"
Mixtral's Response:


Observation: Mistral offered an elaborate but misguided explanation. It described the performance of various language models on the MMLU multiple-choice exam, discussing topics like benchmark performances and the number of shots used. This response, while detailed, did not align with the query's focus on the Gemini Technical Report, indicating a misinterpretation of the question's context.
OpenAI GPT-3.5's Response:


Observation: Interestingly, GPT-3.5 reverted to Spanish for its answer, despite the question being in English. It provided a thorough summary of the Gemini report, focusing on the Gemini models' advancements and their applications across different domains. The response highlighted the models' breakthroughs in understanding and generating multimodal content, as well as discussing the limitations and potential areas for further research in language models.
Final Thoughts on the English Queries:
Mistral's ability to provide relevant answers varied, showing a need for improvement in context understanding, especially in multilingual settings. Meanwhile, GPT-3.5's unexpected language switch suggested a potential influence of prior Spanish prompts, an intriguing aspect of language model behavior.
Testing with a Spanish Document: "Código de Tránsito Colombia"
To further probe their multilingual capabilities, I provided the models with a Spanish document and asked a general question about its content.
Mixtral's Response:
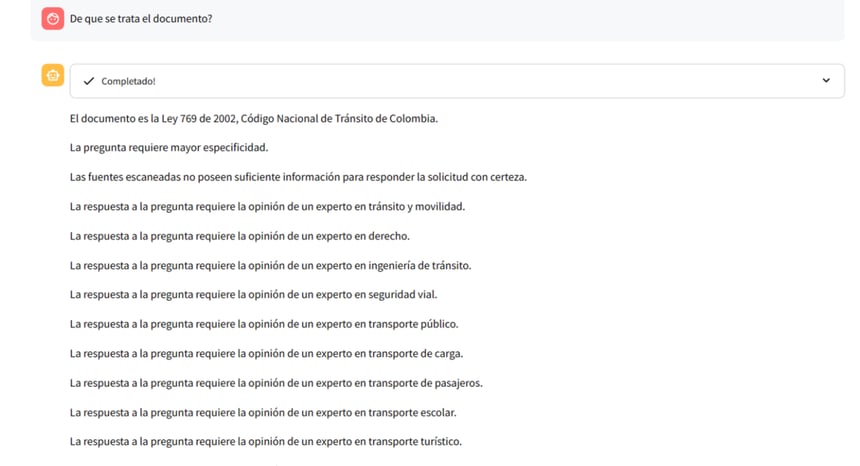
Observation: Mistral struggled to provide a concise summary, instead listing the need for expert opinions in various related fields, indicating a challenge in directly addressing the content.
OpenAI GPT-3.5's Response:


Observation: GPT-3.5 effectively summarized the document, accurately describing it as Colombia's National Traffic Code and outlining its key components and regulations.
Final Thoughts:
Mixtral appears to struggle with clear, context-focused answers, especially when dealing with multiple languages. OpenAI, despite consistently providing accurate responses, sometimes did not match the language of the original question. This highlights an area for improvement in both models, particularly in handling questions across different languages more effectively.
A note on Mistral AI:
The work that the Mistral team has done is amazing, and I believe it's one of the best AI companies in the market, especially for their contributions to the Open Source Community. While this comparison might suggest that Mistral isn't quite there yet, it's important to remember the following: these models are only going to get better from here, so there's a bright future ahead!